
Technical Interview Best Practices: The Complete 2026 Guide for Engineering Leaders
Here is a sobering statistic: 52% of job seekers have declined an offer due to poor candidate experience in the hiring process, according to CareerPlug’s 2024 Candidate Experience Report. For engineering leaders, this translates to losing exceptional talent before they ever join your team—not because of compensation or the role itself, but because your interview process failed to engage, respect, or accurately assess them.
This comprehensive guide examines what the research actually says about technical interviewing. We will move beyond opinions and anecdotes to explore evidence-based practices that predict job performance, reduce bias, and create a candidate experience that top engineers actually want to complete. Whether you are building your first technical interview process or refining an existing one, the frameworks and data here will help you make decisions grounded in science rather than convention.
Why Most Technical Interviews Fail
The software industry has spent decades perfecting the art of the technical interview, yet the results remain disappointing. Companies routinely reject candidates who would have excelled in the role while hiring others who underperform. The cost of these errors extends far beyond the immediate hiring decision—false negatives mean missing out on exceptional talent, while false positives drain team productivity and morale.
Understanding why interviews fail requires examining the research on predictive validity. In industrial-organizational psychology, predictive validity refers to how well a selection method forecasts actual job performance. The higher the validity coefficient, the better the method predicts who will succeed.
Frank Schmidt and John Hunter’s seminal 1998 meta-analysis, which synthesized 85 years of research findings, established clear hierarchies among selection methods. Their work has been validated and refined by subsequent research, including Sackett et al.’s 2021 updates. The findings are clear: not all interview formats are created equal, and many popular approaches have surprisingly low validity.

The Validity Hierarchy
Research consistently shows that unstructured interviews—conversations where interviewers ask whatever comes to mind—have a validity coefficient of approximately 0.38. This means they explain only about 14% of the variance in job performance. While better than random chance, unstructured interviews are significantly outperformed by more rigorous methods.
Structured interviews, where all candidates receive the same questions in the same order and are evaluated using standardized scoring rubrics, achieve validity coefficients around 0.51. This represents a 34% improvement over unstructured approaches and explains roughly 26% of performance variance.
Work sample tests, which require candidates to perform tasks representative of actual job duties, show the highest validity at approximately 0.54. These assessments directly measure whether candidates can do the work, making them the strongest single predictor of job performance available to hiring teams.
| Selection Method | Validity Coefficient | Variance Explained | Research Source |
|---|---|---|---|
| Work Sample Tests | 0.54 | 29% | Schmidt & Hunter (1998); Roth et al. meta-analysis |
| Structured Interviews | 0.51 | 26% | Schmidt & Hunter (1998); McDaniel et al. (1994) |
| Cognitive Ability Tests | 0.51 | 26% | Schmidt & Hunter (1998) |
| Unstructured Interviews | 0.38 | 14% | Huffcutt & Arthur (1994) |
| Years of Experience | 0.18 | 3% | Schmidt & Hunter (1998) |
| Years of Education | 0.10 | 1% | Schmidt & Hunter (1998) |
The implications are profound. Factors that many hiring teams overweight—years of experience, educational pedigree, even the impression a candidate makes in casual conversation—have minimal predictive power. Meanwhile, structured assessments of actual job-relevant skills provide significantly better forecasts of who will perform well.
Why Unstructured Interviews Persist
Given the clear superiority of structured methods, why do unstructured interviews remain so common? The answer lies in a combination of organizational inertia, misconceptions about assessment, and the genuine appeal of conversational interviews.
Many hiring managers believe that unstructured interviews allow them to “get a feel” for candidates or assess “cultural fit” in ways that structured methods cannot. The research contradicts this intuition. Studies show that impressions formed in unstructured interviews correlate more with interviewer mood, candidate attractiveness, and similarity to the interviewer than with actual job performance.
Another barrier is the effort required to implement structured interviews. Creating standardized questions, training interviewers, and developing rubrics takes time. Organizations that view hiring as a distraction from “real work” often resist this investment, preferring the apparent efficiency of informal conversations.
The reality is that unstructured interviews are efficient only in the short term. The cost of a bad hire—estimated at 30% of annual salary for entry-level positions and significantly more for senior roles—far exceeds the investment required to build a structured process. When you factor in the cost of false negatives, the business case for structure becomes overwhelming.
The Business Case for Interview Excellence
Beyond predictive validity, interview quality directly impacts business outcomes through candidate experience, time-to-hire, and offer acceptance rates. The data tells a clear story about what happens when companies get this wrong.
According to the 2024 Candidate Experience Report from CareerPlug, 52% of job seekers have declined an offer due to poor candidate experience. This is not a marginal concern—it affects the majority of hiring outcomes. The same research found that 60% of job seekers report having negative candidate experiences with employers they engaged.
Cronofy’s 2024 Candidate Expectations Report reveals that 42% of candidates leave the recruitment process when it takes too long to schedule an interview. In a competitive market for engineering talent, this friction alone eliminates nearly half of your potential hires before they ever speak with your team.
The time dimension compounds these challenges. The average time-to-hire for software engineers ranges from 35 to 44 days according to multiple industry sources. During this period, top candidates receive multiple competing offers. A slow, disorganized interview process does not just test patience—it actively drives candidates toward faster-moving competitors.

The Cost of False Negatives
False negatives—rejecting candidates who would have excelled—receive less attention than false positives, but their cost may be higher. When you reject a strong candidate, you do not just lose that individual. You must continue searching, interviewing, and evaluating until you find an alternative. If strong candidates are rare, each false negative means sifting through dozens more applications.
Research from interviewing.io suggests that in competitive hiring markets, a single false negative can cost the equivalent of reviewing 100 additional candidates. For specialized engineering roles where qualified applicants are scarce, this cost multiplies. The engineer you rejected yesterday may be building critical infrastructure for your competitor today.
The hidden cost of false negatives extends to team morale and velocity. When teams are understaffed due to overly selective hiring, existing engineers bear the burden of increased workload. Projects slip, burnout increases, and your best people may start looking elsewhere. A hiring process that is too risk-averse creates the very problems it was designed to prevent.
The Interview-to-Offer Funnel
Ashby’s 2025 recruiting benchmarks provide sobering data on interview efficiency. Their analysis shows interview-to-offer rates of roughly 7% for technical roles, compared to 9% for business roles. This means that for every 100 candidates who complete technical interviews, only 7 receive offers.
This low conversion rate has two possible interpretations. The optimistic view is that technical interviews are appropriately selective, filtering out candidates who lack necessary skills. The pessimistic view—and the one supported by research on interview validity—is that many qualified candidates are being rejected due to poor assessment methods.
Improving interview validity does not necessarily mean lowering standards. It means distinguishing more accurately between candidates who can do the work and candidates who cannot. A structured interview process with validity of 0.51 will make better distinctions than an unstructured process with validity of 0.38, even when both are trying to assess the same competencies.
Designing the Structured Technical Interview
Structured interviews represent the gold standard for predictive validity in face-to-face assessment. Unlike unstructured conversations, they follow a rigorous methodology that reduces bias, improves consistency, and generates measurable outcomes.
The research on structured interviews distinguishes between two primary question types: behavioral and situational. Behavioral questions ask candidates to describe past experiences: “Tell me about a time when you had to optimize a slow database query.” Situational questions present hypothetical scenarios: “How would you approach scaling a service that suddenly needs to handle 10x traffic?”
Both approaches have demonstrated validity, though behavioral questions typically show slightly higher predictive power for experienced candidates who have relevant past experiences to draw upon. Situational questions can be more appropriate for junior candidates or when assessing responses to novel scenarios.
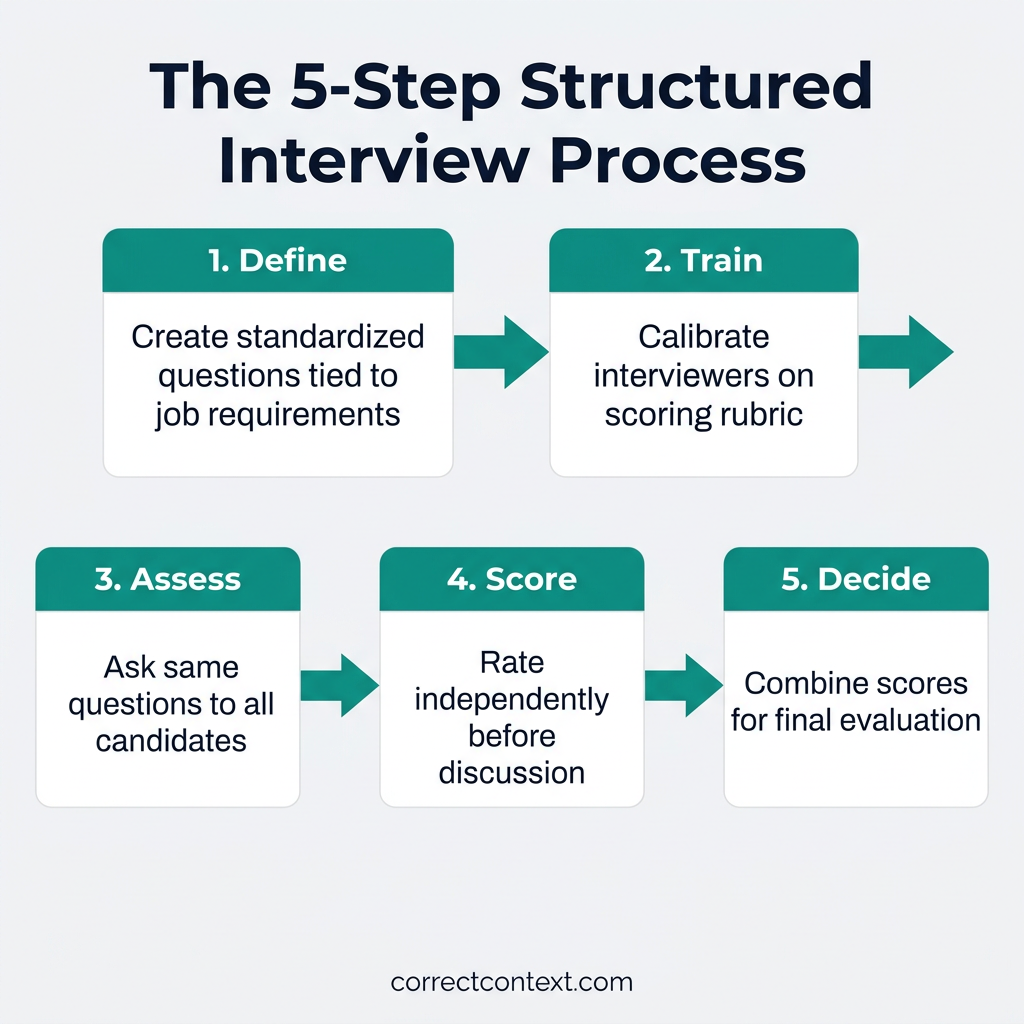
The Five-Step Structured Interview Framework
Implementing structured interviews requires a systematic approach. The following framework, derived from research by industrial-organizational psychologists and validated at organizations including Google, provides a template for building rigorous assessment processes.
Step 1: Define Job Requirements and Competencies
Before writing a single interview question, document the specific competencies required for success in the role. These should be derived from job analysis—examining what high performers actually do—rather than generic assumptions about what engineers need to know.
For a backend engineering position, relevant competencies might include: distributed systems design, database optimization, API design, debugging complex issues, and collaborative code review. Each competency should have clear behavioral indicators that distinguish strong from weak performance.
The competency definition phase is often rushed or skipped entirely, but it is foundational. Without clear understanding of what you are assessing, you cannot create effective questions or rubrics. Invest time here to save time and improve quality throughout the rest of the process.
Step 2: Develop Standardized Questions and Scoring Rubrics
Create questions that directly assess the competencies identified in Step 1. Each question should be designed to elicit specific, observable behaviors that can be evaluated against predefined criteria.
The scoring rubric is critical. Instead of vague impressions, define what constitutes a 1, 3, or 5 response for each question. For example, when assessing system design, a 1 might indicate no consideration of scalability, a 3 might show awareness but limited depth, and a 5 might demonstrate sophisticated trade-off analysis with specific technical recommendations.
Rubrics should be behaviorally anchored, meaning they describe specific actions or statements rather than abstract qualities. “Demonstrated understanding of database indexing” is more useful than “showed technical knowledge.” The more specific your rubric, the more consistent your ratings will be across interviewers.
Step 3: Train Interviewers
Interviewers must understand both the questions and the rubric. Training should include practice sessions where interviewers evaluate recorded responses and compare their ratings against expert benchmarks. Research shows that trained interviewers produce significantly more reliable ratings than untrained ones.
Training should also cover common biases. Halo effects (where one strong answer influences ratings on other questions), contrast effects (where the previous candidate influences the current evaluation), and similarity bias (favoring candidates who remind us of ourselves) can all be mitigated through awareness and structured scoring.
Google’s research on structured interviewing found that interviewer training was one of the highest-impact investments they made in improving hiring quality. Even experienced engineers benefit from calibration on what good and bad responses look like for specific questions.
Step 4: Conduct Interviews Consistently
Every candidate for the same role should receive identical questions in the same order. This standardization is what transforms subjective conversations into reliable measurement instruments.
Interviewers should take detailed notes on candidate responses rather than relying on memory. These notes serve two purposes: they improve rating accuracy by capturing specific evidence, and they provide documentation for hiring decisions if challenged.
Consistency also applies to logistics. Every candidate should have the same time allocation, the same environment, and the same opportunity to ask questions. Variation in these factors introduces noise that obscures true differences in candidate ability.
Step 5: Score Independently, Then Discuss
Each interviewer should complete their ratings independently before any group discussion. This prevents groupthink and ensures that each interviewer’s assessment reflects their own evaluation rather than influence from colleagues.
After independent scoring, interviewers can convene to discuss discrepancies. The goal is not to reach consensus at all costs, but to understand why ratings differ and whether additional evidence should be considered. The final hiring decision should integrate structured ratings with other relevant information.
Research on group decision-making shows that structured aggregation of independent judgments typically outperforms unstructured group discussion. Consider using mechanical combination of scores (averaging or summing) as a starting point for decision-making, with discussion reserved for cases where scores are borderline or inconsistent.
Live Coding vs. Take-Home Assignments
The debate between live coding interviews and take-home assignments has generated considerable discussion in the engineering community. Each approach has strengths and weaknesses, and the research provides guidance on when to use each.
Live coding interviews, conducted in real-time with an interviewer present, allow for immediate clarification of requirements and observation of a candidate’s thought process. They cannot be completed by someone other than the candidate, addressing concerns about authenticity. However, they also create time pressure that may not reflect actual working conditions.
Take-home assignments provide candidates with more time to craft solutions and can assess skills that require sustained effort, such as building a small application or refactoring a codebase. However, they demand more candidate time—often 4-8 hours—and raise concerns about fairness for candidates with caregiving responsibilities or limited free time.
| Assessment Type | Strengths | Weaknesses | Best For |
|---|---|---|---|
| Live Coding (45-60 min) | Authentic; assesses communication; prevents cheating | Time pressure; limited scope; interview anxiety | Algorithms, debugging, pair programming skills |
| Take-Home (4-8 hours) | Realistic tasks; sustained effort; portfolio piece | Time burden; authenticity concerns; delayed feedback | System design, full-stack projects, code quality |
| Work Sample (2-4 hours) | Highest predictive validity; job-relevant | Requires careful design; may narrow candidate pool | Role-specific skills; senior positions |
| Code Review (30-45 min) | Assesses real-world skills; collaborative | Limited to existing codebases; less creative | Senior roles; mentorship skills; quality standards |
The Hybrid Approach
Many leading engineering organizations have moved toward hybrid models that combine elements of different assessment types. A typical structure might include:
An initial 30-minute technical screen using a simple live coding exercise to establish baseline competency. This filters out candidates who lack fundamental skills while requiring minimal time investment from either party.
A structured behavioral interview assessing past experiences and collaborative skills. This evaluates competencies like communication, conflict resolution, and technical leadership that coding exercises cannot capture.
A work sample assessment—either take-home or in-person—evaluating job-specific skills. For a backend role, this might involve designing an API; for a frontend role, implementing a user interface based on a design specification.
A final system design or architecture discussion for senior candidates, assessing their ability to think broadly about technical trade-offs and scale.
This multi-method approach leverages the strengths of each assessment type while mitigating individual weaknesses. It also provides multiple data points for decision-making, reducing the risk of false negatives caused by a single bad interview day.
Designing Effective Live Coding Exercises
When using live coding, exercise design determines validity. Poorly designed exercises assess speed under pressure rather than job-relevant skills. Effective exercises share several characteristics.
First, they focus on problems similar to those the candidate would actually encounter on the job. For a data engineering role, this might involve processing a dataset; for a backend role, designing an API endpoint. Abstract algorithm puzzles that bear no resemblance to actual work should be avoided.
Second, they allow candidates to demonstrate their thinking, not just their output. The goal is not to see whether the candidate can produce working code in 45 minutes—anyone can memorize solutions. The goal is to understand how they approach problems, what questions they ask, and how they respond to feedback.
Third, they are calibrated against actual job requirements. Before using an exercise, test it with current employees. If your senior engineers struggle with the problem, it is likely too difficult. If your junior engineers solve it instantly, it is likely too easy.
Reducing Bias in Technical Assessment
Unconscious bias affects every stage of the hiring process, and technical interviews are no exception. Research from interviewing.io found significant disparities in interview outcomes based on gender, with women receiving lower scores even when their code was identical to men’s. The good news is that structured processes can substantially reduce these biases.
CodeSignal’s Talent Science team has identified evidence-based practices for advancing diversity in technical hiring. Their research, combined with broader findings from industrial-organizational psychology, points to several high-impact interventions.
Structured Questions and Rubrics
The same standardization that improves predictive validity also reduces bias. When all candidates answer identical questions and are evaluated against predefined criteria, there is less opportunity for subjective impressions to influence decisions. Research shows that structured interviews produce smaller group differences than unstructured ones while maintaining or improving validity.
Diverse Interview Panels
Assembling interview panels with diverse backgrounds reduces the impact of individual biases. When panel members represent different perspectives, they are more likely to catch each other’s blind spots. Research also suggests that candidates from underrepresented groups may perform better when they see people like themselves in the interview process.
WomenTech Network’s research on diverse interview panels highlights that mixed-gender panels produce more balanced assessments and improve candidate experience for underrepresented groups. The presence of diversity on the panel signals that the organization values inclusion.
Blind Review Where Possible
For work sample tests and coding assignments, consider blind evaluation where the reviewer does not know the candidate’s name, background, or demographics. This eliminates several categories of bias while maintaining assessment quality.
Several platforms now offer automated code evaluation that scores submissions based on objective criteria like test passage, code complexity, and documentation quality. While automated evaluation should not replace human judgment entirely, it can provide a bias-free input to the decision process.
Calibration and Monitoring
Regularly analyze hiring data to detect bias patterns. Are candidates from certain backgrounds receiving systematically different scores? Are pass rates consistent across demographic groups? Data-driven monitoring enables continuous improvement and early detection of problems.
LinkedIn’s 2025 Future of Recruiting report emphasizes that AI-driven hiring tools, while potentially beneficial, require careful monitoring for bias. The same applies to human-driven processes. What gets measured gets managed.
The STAR Method for Behavioral Assessment
For behavioral interview questions, the STAR method provides a framework for both asking and evaluating responses. Developed by DDI (Development Dimensions International), STAR stands for Situation, Task, Action, and Result.
A well-constructed behavioral question asks candidates to describe a specific past experience: “Tell me about a time when you had to debug a production issue under time pressure.” The candidate’s response should then be evaluated for completeness across the STAR dimensions.
Situation: Did the candidate clearly describe the context? A strong response establishes what was happening, who was involved, and what was at stake. Vague or missing context suggests the candidate is either fabricating or does not understand what made the situation significant.
Task: What was the candidate’s specific responsibility? Strong candidates articulate their role rather than describing team activities in the abstract. Look for “I” statements that clarify individual contribution versus “we” statements that obscure it.
Action: What did the candidate actually do? This is the core of the response, where candidates demonstrate their skills through specific behaviors. Strong responses include detailed descriptions of steps taken, tools used, and decisions made.
Result: What was the outcome? Strong candidates describe measurable results and reflect on what they learned. Be wary of responses that end with “and then we fixed it” without specifics about impact.
Research on the STAR method, including studies from Southern University and A&M College, confirms that structured behavioral interviewing improves both reliability and validity compared to unstructured approaches. The method also helps interviewers stay focused on evidence rather than impressions.
Common STAR Pitfalls
Candidates often struggle with behavioral questions, even when they have relevant experience. Common pitfalls include:
Hypothetical responses: When asked for a specific example, candidates describe what they would do rather than what they did. Gently redirect: “That sounds like a good approach, but can you tell me about a time you actually faced this situation?”
Team accomplishments: Candidates describe what “we” did without clarifying their individual contribution. Probe for specifics: “What was your specific role in that project? What did you personally work on?”
Incomplete stories: Candidates describe situations and actions but omit results. Ask directly: “What was the outcome? How did you know you succeeded?”
Over-rehearsed responses: Some candidates prepare stories that sound polished but lack substance. Push for details: “Walk me through the specific code changes you made” or “What exactly did you say in that conversation?”
System Design Interviews for Senior Engineers
For senior engineering positions, system design interviews have become standard practice. Unlike coding exercises that assess implementation skills, system design interviews evaluate architectural thinking, trade-off analysis, and the ability to build scalable systems.
The research on system design interview validity is less extensive than for general structured interviews, but practitioner experience and theoretical considerations suggest they provide valuable signal for senior roles. The key is designing questions that reflect actual job requirements rather than theoretical puzzles.
Effective system design interviews assess several competencies:
Requirements Clarification: Does the candidate ask clarifying questions about scale, latency requirements, and functional needs before diving into solutions? Junior candidates often start drawing boxes and arrows immediately; senior candidates clarify scope first.
Architecture Design: Can the candidate propose a reasonable high-level design that addresses the stated requirements? Look for appropriate component separation, clear data flow, and consideration of failure modes.
Trade-off Analysis: Does the candidate understand the trade-offs between different approaches and make reasoned choices? Strong candidates explain why they chose SQL over NoSQL, or synchronous over asynchronous communication, with reference to specific requirements.
Deep Dive Capability: Can the candidate go deep on specific components when prompted, discussing database choice, caching strategy, or API design? Breadth without depth suggests theoretical knowledge without practical experience.
Operational Thinking: Does the candidate consider monitoring, error handling, and deployment concerns? Systems that cannot be operated in production are not complete designs.
Research from ByteByteGo and other technical interview platforms suggests that the best system design questions are open-ended enough to allow candidates to demonstrate depth while specific enough to enable consistent evaluation. Questions like “Design a URL shortener” or “Design a distributed cache” have become standard because they meet these criteria.
Evaluating System Design Responses
System design interviews require different rubrics than coding exercises. Consider evaluating across dimensions like:
Problem understanding: Did the candidate identify the right requirements and constraints?
Architecture quality: Is the proposed design reasonable, with appropriate component separation and clear interfaces?
Scalability awareness: Did the candidate discuss how the system would handle growth in users, data, or traffic?
Trade-off reasoning: Were decisions justified with reference to requirements rather than personal preference?
Operational maturity: Did the candidate consider monitoring, deployment, and failure handling?
Communication clarity: Was the candidate able to explain their thinking clearly and respond to challenges constructively?
Measuring and Improving Interview Quality
Building an effective interview process is not a one-time project but a continuous improvement cycle. High-performing engineering organizations regularly measure interview outcomes and refine their approaches based on data.
Completion Rates
Track what percentage of candidates who start your interview process complete it. Low completion rates may indicate excessive time requirements, poor communication, or scheduling friction. Research from Pin (2026) found that the interview stage accounts for 32% of all candidate drop-off.
Monitor completion rates by stage. If many candidates drop off after receiving take-home assignments, the time requirement may be too high. If they drop off after initial screens, your screening may be too broad or your communication too slow.
Interview-to-Offer Ratios
Ashby’s 2025 recruiting benchmarks show interview-to-offer rates of roughly 7% for technical roles. If your rate is significantly lower, your screening may be too loose. If it is much higher, you may be filtering out qualified candidates prematurely.
Track this metric by interviewer and by question. If one interviewer’s candidates consistently receive lower ratings than others, calibration may be needed. If one question produces no variance (everyone gets the same score), it may not be discriminating effectively.
Offer Acceptance Rates
Track what percentage of offers are accepted. Low acceptance rates may indicate compensation misalignment, but they often signal candidate experience problems. The 52% of candidates who decline offers due to poor experience represent a critical metric for interview quality.
Survey candidates who decline offers to understand why. If they consistently mention interview experience, you have a clear priority for improvement.
New Hire Performance Correlation
The ultimate test of interview validity is whether candidates who score well actually perform well. After new hires have been in role for 6-12 months, correlate their interview scores with their performance ratings. If the correlation is weak, your interview process needs refinement.
This analysis can identify which interview questions or competencies actually predict performance. You may find that some questions you thought were important have no correlation with success, while others you undervalued are highly predictive.
Candidate Feedback
Survey all candidates—not just those who receive offers—about their interview experience. Questions should assess perceived fairness, clarity of expectations, and whether the process accurately represented the role. Negative feedback is a gift that reveals opportunities for improvement.
Stack Overflow’s 2024 Developer Survey found that developer experience at work—including hiring processes—significantly impacts retention and satisfaction. Candidates who have positive interview experiences become employees who are more engaged from day one.
Key Takeaways
- Structure beats intuition. Structured interviews with standardized questions and scoring rubrics achieve validity coefficients of 0.51, compared to 0.38 for unstructured interviews. The 34% improvement in predictive power translates directly to better hiring decisions.
- Work samples predict best. Work sample tests show the highest validity (0.54) of any single assessment method. Whenever possible, include job-relevant tasks that mirror actual work.
- Candidate experience is business-critical. 52% of job seekers decline offers due to poor candidate experience, and 42% abandon processes that take too long to schedule. Every friction point in your process costs you talent.
- Standardization reduces bias. Structured interviews with diverse panels and blind evaluation where possible significantly reduce demographic disparities in hiring outcomes while maintaining or improving validity.
- The STAR method works. For behavioral assessment, the Situation-Task-Action-Result framework improves both reliability and validity while keeping interviews focused on evidence.
- Multi-method assessment is strongest. Combine live coding, behavioral interviews, and work samples to leverage the strengths of each approach while mitigating individual weaknesses.
- Measure and improve continuously. Track completion rates, interview-to-offer ratios, and new hire performance correlation. Use candidate feedback to identify friction points.
Frequently Asked Questions
How long should a technical interview process take?
Research indicates that the average time-to-hire for software engineers is 35-44 days. However, speed matters—42% of candidates abandon processes that take too long to schedule. Aim to complete your entire interview process within 2-3 weeks from initial screen to offer. This requires disciplined scheduling, prompt feedback, and parallel rather than sequential interview stages.
Are LeetCode-style algorithm questions effective?
The research on algorithm questions specifically is limited, but the broader pattern is clear: assessments that closely mirror job requirements have higher validity than abstract puzzles. For roles involving algorithmic optimization or competitive programming, LeetCode-style questions may be relevant. For most software engineering positions, work samples and system design questions that reflect actual job tasks are likely more predictive.
How many interviewers should be involved in each assessment?
Research on interview panels suggests that 2-3 trained interviewers per session provides good reliability without excessive coordination costs. For final decisions, involving 4-6 interviewers across multiple sessions reduces individual bias while maintaining reasonable process length. The key is ensuring all interviewers use standardized rubrics and complete independent ratings before discussion.
Should we give candidates feedback on their performance?
While not required, providing constructive feedback improves candidate experience and can strengthen your employer brand. Candidates who receive feedback—even when rejected—are more likely to recommend your company to others. However, feedback should be specific, behavioral, and focused on areas for development rather than personal criticism.
How do we balance thoroughness with candidate experience?
The tension between comprehensive assessment and respectful process is real. The solution is ruthless prioritization: assess only the competencies that truly matter for the role, use efficient assessment methods, and eliminate redundant interviews. Every hour you ask of candidates should provide meaningful signal. If an interview stage does not change hiring decisions, remove it.
What about AI in technical interviewing?
AI-powered interview tools are proliferating, but the research on their effectiveness is mixed. While AI can reduce bias in resume screening and provide consistent evaluation of structured assessments, it cannot replace human judgment in evaluating communication, collaboration, and cultural fit. Use AI as a tool to augment rather than replace structured human assessment. Monitor AI systems carefully for bias, as they can perpetuate and amplify biases present in training data.
Sources
- CareerPlug — 2024 Candidate Experience Report (2024)
- Cronofy — Candidate Expectations Report 2024 (2024)
- Zivaro — Structured vs Unstructured Interviews: What the Research Actually Says (2024)
- Schmidt, F.L., & Hunter, J.E. — The Validity and Utility of Selection Methods in Personnel Psychology: Practical and Theoretical Implications of 85 Years of Research Findings. Psychological Bulletin, 124(2), 262-274 (1998)
- DDI — STAR Method for Interviewing and Feedback (2024)
- Ashby — 2025 Recruiting Metrics Report (2025)
- Stack Overflow — 2024 Developer Survey (2024)
- LinkedIn — The Future of Recruiting 2025 (2025)
- WomenTech Network — How Diverse Interview Panels Improve Equity (2024)
- ByteByteGo — A Framework for System Design Interviews (2024)
- Noxx — What Is the Average Time to Hire Software Engineer (2024)
- Skillflow — AI & Coding Interview Statistics 2026 (2026)
Ready to improve your technical hiring process? Correct Context helps companies build world-class engineering teams in Poland and the CEE region. Our full-cycle hiring process includes structured technical assessments, behavioral interviews, and work sample evaluations—delivering qualified candidates in 2-6 weeks with a 98% probation pass rate. Contact us to learn how we can help you hire better, faster.
Table of content
- Why Most Technical Interviews Fail
- The Business Case for Interview Excellence
- Designing the Structured Technical Interview
- Live Coding vs. Take-Home Assignments
- Reducing Bias in Technical Assessment
- The STAR Method for Behavioral Assessment
- System Design Interviews for Senior Engineers
- Measuring and Improving Interview Quality
- Key Takeaways
- Frequently Asked Questions
- How long should a technical interview process take?
- Are LeetCode-style algorithm questions effective?
- How many interviewers should be involved in each assessment?
- Should we give candidates feedback on their performance?
- How do we balance thoroughness with candidate experience?
- What about AI in technical interviewing?
- Sources
Related articles



About the Author: Duke Vu

