
10 Proven Strategies for Scaling Engineering Teams from 5 to 50 Developers (2026 Guide)
Here is a statistic that should concern every CTO planning to grow their team: 68% of engineering teams report increased technical debt during rapid scaling phases. The very growth that promises to accelerate your product development often creates the conditions that slow it down. This is the scaling paradox — and it catches most engineering leaders by surprise.
Scaling an engineering team from 5 to 50 developers is one of the most challenging transitions in a company’s lifecycle. At 5 engineers, everyone knows everything. Communication is organic. Decisions happen in hallway conversations. Code quality is maintained through shared context and mutual accountability. At 50 engineers, those same patterns break down. Communication paths multiply exponentially. Context fragments across specialized teams. Code quality depends on processes, not personal relationships.
This guide presents 10 proven strategies for navigating this transition. These are not theoretical frameworks — they are battle-tested approaches from companies that have successfully scaled, backed by data from engineering research and real-world case studies. Whether you are at 10 engineers planning for 30, or at 30 trying to get to 50, these strategies will help you scale without sacrificing the speed and quality that made you successful.
Why Scaling Engineering Teams Is Different From Other Growth
Engineering teams are not like sales teams or marketing teams. You cannot simply hire more people and expect linear output growth. Software development is a complex, collaborative activity where adding people often initially reduces productivity before eventually increasing it. This is Brooks’s Law, first articulated in 1975: “Adding manpower to a late software project makes it later.”
The reasons are well understood but often ignored. New engineers need to be onboarded, which takes time from existing engineers. Communication paths increase quadratically with team size — a 5-person team has 10 potential pairwise conversations, while a 50-person team has 1,225. Codebases become more complex as more hands touch them. Technical debt accumulates faster when multiple teams work on shared systems without coordination.
What makes scaling particularly challenging is that the practices that work at small scale often become anti-patterns at large scale. At 5 engineers, flexibility and improvisation are strengths. At 50, they become sources of inconsistency and confusion. At 5, everyone can hold the entire system in their head. At 50, no one can — which means documentation, architecture decisions, and explicit processes become essential.
The companies that scale successfully recognize this transition and proactively change how they work. They do not wait for things to break. They anticipate the challenges and build systems to address them before they become crises.
1. Hire Engineering Managers Before You Think You Need Them
The most common mistake in engineering scaling is delaying management hires until the team is already struggling. By the time you recognize you need engineering managers, your best developers are already burning out from trying to code and manage simultaneously.
Data from Jellyfish’s 2025 analysis of 445 companies reveals a striking pattern: early-stage companies (Seed, Series A, Series B) operate with manager-to-engineer (MtE) ratios of 1:7.5 on average, while later-stage companies maintain ratios of 1:4.6. This suggests that young startups often delay management investment until forced by crisis, while mature companies proactively invest in leadership structure.
The cost of waiting is measurable. Among engineers who left their companies, 64% had managers with MtE ratios higher than the company average. Engineers whose managers had 10 or more direct reports stayed an average of four months less than the baseline. When managers are stretched thin, they cannot provide mentorship, code review, or career development — and engineers leave.
The research also shows that early-stage companies do not always have flat cultures with low MtE ratios. In fact, Seed through Series B companies have much higher MtE ratios than later-stage companies. This suggests that young startups might have to operate more flatly out of necessity, while more mature companies are able to reinvest in leadership structures as they scale.
Microsoft research from 2008 found that teams with managers overseeing more than 10 engineers consistently reported higher rates of defects. The problem was not the process of the team — it was caused by the fact that the managers simply did not have the bandwidth for mentorship and code review, and quality quietly suffered as a result.
The rule: Hire your first engineering manager when you hit 8-10 engineers. Not when you hit 15 and everything is on fire. The manager’s job is not to write code — it is to multiply the effectiveness of the team. That multiplication starts paying off immediately, not eventually.
When hiring your first engineering manager, look for someone who can still contribute technically while building management skills. They should have experience mentoring others, making architectural decisions, and communicating with non-technical stakeholders. The transition from senior engineer to engineering manager is challenging — provide support through coaching, peer networks, and clear expectations.
2. Structure Teams Around Missions, Not Functions
As you grow, the question of how to organize teams becomes critical. The wrong structure creates coordination overhead, slows decision-making, and fragments accountability. The right structure enables autonomy, speeds delivery, and maintains alignment.
The Spotify model — squads, tribes, chapters, and guilds — has become influential for good reason. It addresses the core challenge of scaling: maintaining alignment without sacrificing autonomy. Squads are cross-functional teams (6-12 people) with a clear mission. Tribes are collections of related squads (under 100 people) working in the same business area. Chapters are groups of specialists (frontend engineers, data scientists) who share practices across squads. Guilds are communities of interest that span the entire organization.
The key insight is not to copy Spotify’s structure exactly — it was designed for their specific context — but to understand the principles. Organize teams around missions (outcomes) rather than functions (activities). Keep teams small enough that everyone knows what everyone else is doing. Create mechanisms for sharing knowledge across team boundaries. Maintain alignment through shared purpose rather than centralized control.
For a team scaling from 5 to 50, the progression typically looks like this: At 5-10 engineers, you have one team with shared context. At 10-20, you split into 2-3 mission-based teams. At 20-35, you formalize the tribe structure with 4-6 teams. At 35-50, you add platform teams and guilds to manage cross-cutting concerns.
When splitting teams, do not organize by technical layer (frontend team, backend team, database team). This creates dependencies and handoffs that slow delivery. Instead, organize by business capability or user journey. A “Checkout Team” owns everything from the payment UI to the transaction processing. A “Search Team” owns the search interface, the query engine, and the indexing pipeline. This end-to-end ownership reduces coordination overhead and creates clear accountability.

3. Invest in Developer Onboarding Like Your Velocity Depends On It
When you are 5 engineers, onboarding is easy. The new hire sits next to the founder, pairs on everything, and absorbs context through osmosis. When you are 50 engineers, onboarding is a system — and most companies build that system reactively, after multiple failed onboarding experiences.
Research on developer onboarding shows that structured programs dramatically accelerate time-to-productivity. Companies with strong onboarding practices see new hires reach full productivity in 30-60 days, compared to 6+ months with ad-hoc approaches. The difference is not the intelligence or capability of the hires — it is the clarity of expectations, the quality of documentation, and the availability of support.
A 90-day onboarding protocol should include: Day 1-3 — environment setup, codebase orientation, first commit; Week 1-2 — pairing with onboarding buddy, first independent task; Day 30 — first code review cycle under two days, bug rate below 5%; Day 60 — test coverage above 80%, independent feature delivery; Day 90 — full team integration, mentorship of next new hire.
Key metrics to track: time-to-first-commit (should be under 2 hours), new hire Net Promoter Score, and 90-day retention rates. Companies with strong onboarding see 95% retention at 90 days and 87% at one year.
The onboarding buddy system is particularly effective. Assign every new hire a peer buddy — not their manager — who helps them navigate the first 90 days. The buddy answers questions, provides context, and introduces them to the team. This reduces the burden on managers and gives new hires a safe person to ask “dumb questions.” Netflix’s “Peers” program connects new hires with colleagues in similar roles, easing first-day nerves and building confidence during onboarding.
Documentation is the foundation of scalable onboarding. Maintain a “New Hire Guide” that covers: development environment setup, codebase architecture overview, team processes and norms, key contacts and resources, and common pitfalls and how to avoid them. Update this guide continuously as the system evolves.
4. Enforce Small Pull Requests — Quality Depends On It
As teams scale, code review becomes a bottleneck. The natural response is to batch changes into larger pull requests to “reduce overhead.” This is a mistake. Data from analysis of 50,000+ pull requests across 200+ engineering teams shows that PR size has a dramatic impact on code review effectiveness.
The sweet spot is 200-400 lines of code changed. PRs in this range have 40% fewer defects than larger PRs. Each additional 100 lines increases review time by 25 minutes. Extra large PRs (1000+ lines) average 4.2 hours review time with only 1.8 meaningful comments, compared to 45 minutes and 3.2 comments for small PRs (1-200 lines).
Google’s engineering research found that review quality drops significantly for PRs exceeding 200 lines of changed code. The cognitive load of reviewing large changes exceeds what humans can effectively process. Reviewers either skim (missing issues) or delay (creating bottlenecks).
Enforce small PRs through: PR templates that require description of changes; CI checks that flag oversized PRs; team norms that celebrate small, focused changes; and architectural patterns that enable incremental delivery.
Small PRs require discipline in how work is decomposed. Instead of building an entire feature in one branch, break it into incremental changes: add the database schema; implement the API endpoint; build the UI components; wire everything together. Each step can be reviewed, tested, and deployed independently. This reduces risk and enables faster feedback.
Some changes are inherently large — major refactors, framework upgrades, architectural shifts. For these, use the “stacked PR” pattern: break the change into a series of dependent PRs, each reviewable independently. Tools like GitHub’s stacked PRs or Graphite make this workflow manageable.

5. Build Platform Teams Before You Drown in Toil
At small scale, every team handles its own infrastructure, deployment, and tooling. This works when everyone knows the full stack. It breaks down as teams specialize and the complexity of shared infrastructure exceeds what product teams can manage alongside their feature work.
The solution is a platform team — a dedicated group responsible for the internal developer experience. Platform teams build and maintain the tools, infrastructure, and practices that enable product teams to deliver value faster. They are not an operations team handling tickets; they are a product team whose customers are internal developers.
Platform teams typically emerge when you hit 25-30 engineers. Below that threshold, the overhead of a dedicated platform team exceeds the value. Above it, the accumulated toil of every team managing their own infrastructure becomes a drag on velocity.
Effective platform teams measure their impact through developer productivity metrics: deployment frequency, lead time for changes, mean time to recovery, and change failure rate (the DORA metrics). Their goal is to improve these metrics for product teams, not to optimize infrastructure costs in isolation.
Common platform team responsibilities include: CI/CD pipeline maintenance and optimization; cloud infrastructure and cost management; developer tooling and local environment; observability and incident response; security and compliance automation; and internal libraries and frameworks.
The platform team model requires careful implementation. Platform teams can become bottlenecks if they try to control everything. The better approach is to provide paved roads — easy, well-supported paths for common tasks — while allowing teams to build their own solutions when needed. The goal is to make the default path so good that teams choose it voluntarily.
6. Document Decisions Before You Forget Why You Made Them
At 5 engineers, architectural decisions happen in conversations and live in the heads of the team. At 50 engineers, new team members need to understand why the system is built the way it is — and the original decision-makers may have left or forgotten the rationale.
Architecture Decision Records (ADRs) are a lightweight practice that pays enormous dividends at scale. An ADR is a short document (1-2 pages) that captures: the context that led to a decision; the options considered; the decision made; and the consequences (positive and negative). ADRs are stored in version control alongside code, making them discoverable and maintainable.
The value of ADRs compounds over time. New team members onboard faster by reading the history of decisions. Proposed changes are evaluated against documented rationale. Debates about revisiting old decisions start from a shared understanding of why the decision was made, not from scratch.
Start writing ADRs when you hit 10 engineers. By the time you hit 30, you will have a valuable knowledge base. By 50, it will be essential infrastructure.
Good ADRs follow a consistent template: Title (descriptive); Status (proposed, accepted, deprecated, superseded); Context (what is the issue we are seeing); Decision (what we decided to do); Consequences (what becomes easier/harder). Keep them short — if it takes more than two pages, the decision is probably too big and should be split.
Review ADRs periodically. Mark them as deprecated when the context changes. Link to superseding ADRs when decisions are reversed. Treat them as living documents that evolve with the system.
7. Standardize Tools, Customize Processes
Scaling requires standardization, but the wrong standardization creates resistance and reduces effectiveness. The principle is: standardize tools (to reduce cognitive load and enable mobility), customize processes (to respect team context and autonomy).
Standard tools mean every team uses the same version control, CI/CD platform, monitoring stack, and collaboration tools. This reduces the friction of moving between teams and enables platform teams to build shared infrastructure. It does not mean every team uses the same tools for their specific domain — data teams may need different analytics tools than backend teams.
Custom processes mean teams can adapt their working methods to their context. A team building experimental features may work differently than a team maintaining critical infrastructure. Sprint length, meeting rhythms, and code review practices should fit the team’s work, not be imposed from above.
The boundary between standardized and customized should be clear and documented. When teams request exceptions to standards, evaluate them against the cost of fragmentation. When teams develop effective custom processes, look for opportunities to spread them to other teams through guilds or chapters.
Tool standardization reduces cognitive load. Engineers can move between teams without learning new tools. Platform teams can build automation that works everywhere. Support and training are simplified. The cost is some teams using tools that are not perfectly suited to their work — but the benefits of consistency usually outweigh this cost.
8. Measure What Matters — And Ignore the Rest
As teams scale, the temptation to measure everything grows. More data feels like more control. In practice, excessive measurement creates noise, distracts from important metrics, and can drive gaming behavior.
Focus on a small set of metrics that reflect outcomes, not activities:
| Metric Category | Key Metrics | Why It Matters |
|---|---|---|
| Delivery Performance | Deployment frequency, Lead time for changes | Reflects ability to deliver value quickly |
| Stability | Change failure rate, Mean time to recovery | Reflects quality and resilience |
| Developer Experience | Developer satisfaction, Time to first commit | Reflects onboarding and retention |
| Code Quality | PR review time, Test coverage | Reflects maintainability |
Avoid metrics that drive wrong behaviors: lines of code written (rewards verbosity), number of commits (rewards fragmentation), hours worked (rewards inefficiency), or story points completed (rewards estimation gaming).
Review your metrics quarterly. If a metric is not driving useful conversations and decisions, drop it. If teams are gaming a metric, change it. The goal is insight, not measurement for its own sake.
The DORA metrics (deployment frequency, lead time for changes, change failure rate, mean time to recovery) have become the industry standard for measuring engineering performance. Research shows that high-performing teams deploy on demand, have lead times under one hour, have change failure rates under 5%, and recover from failures in under one hour. These metrics are correlated with organizational performance — companies with high-performing engineering teams have 2.5x higher stock returns over three years.
9. Create Career Paths That Do Not Require Management
The traditional engineering career path forces a choice: stay technical with limited advancement, or move into management to progress. This creates two problems: engineers who would be excellent individual contributors feel forced into management, and engineers who would be excellent managers have no path to develop leadership skills.
Dual career ladders solve this by creating parallel tracks for individual contributors (ICs) and managers. At each level, the compensation and seniority are equivalent, but the responsibilities differ. Senior ICs tackle the hardest technical problems, mentor other engineers, and shape technical strategy. Managers focus on team effectiveness, people development, and organizational alignment.
The key is making the IC track genuinely equivalent to the management track. This means: compensation parity at each level; visibility and influence in technical decisions; opportunities to lead major initiatives; and recognition for technical contributions.
Define the levels clearly. A typical progression might be: Engineer → Senior Engineer → Staff Engineer → Principal Engineer → Distinguished Engineer. Each level should have clear expectations for impact, scope, and technical leadership.
Staff engineers are the bridge between architecture and implementation. They work across teams to solve systemic problems, mentor senior engineers, and represent engineering in cross-functional discussions. Principal engineers shape the technical direction of the entire organization. Distinguished engineers are industry-recognized experts who attract other top talent and represent the company externally.
Career ladders should include both technical competencies (system design, code quality, technical communication) and collaborative competencies (mentoring, cross-team collaboration, knowledge sharing). Advancement requires demonstrating both.
10. Invest in Technical Debt Strategically, Not Reactively
Technical debt is inevitable when scaling. The speed that lets you capture market opportunity creates shortcuts that accumulate as debt. The mistake is treating all debt the same — either ignoring it until it cripples velocity, or trying to eliminate it completely (which slows delivery to a crawl).
Strategic technical debt management means: classifying debt by impact and cost to fix; allocating explicit capacity (typically 20% of sprint capacity) to debt reduction; and making debt visible through code analysis tools and architectural reviews.
Classify debt into categories: Debt that blocks current work (fix immediately); debt that slows future work (schedule for next quarter); debt that is annoying but not blocking (track but defer); and debt that is acceptable trade-offs (document and monitor).
The 68% of teams that see increased technical debt during scaling are often those that deferred all debt management until it became a crisis. The teams that scale successfully treat debt as a normal part of engineering work, managed proactively rather than reactively.
Technical debt is not inherently bad. It is a tool — borrowing against future productivity to achieve current goals. Like financial debt, the problem is not having it, but having too much of it, or the wrong kind, or not knowing how much you have.
Create a technical debt register that tracks: location (which system/component); type (code, architecture, test, documentation); impact (blocks work, slows work, annoying); estimated effort to fix; and priority. Review this register quarterly and allocate capacity based on business priorities.
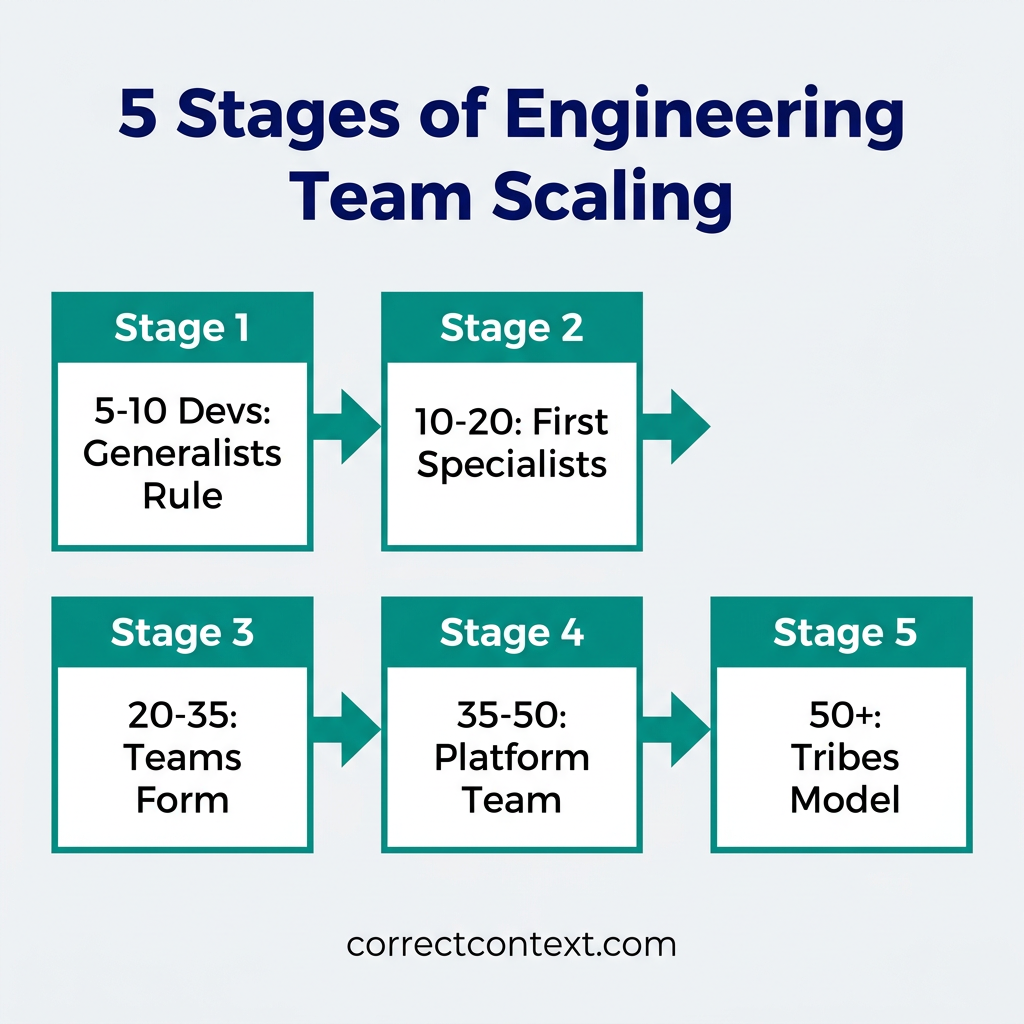
The Scaling Timeline: What to Expect at Each Stage
Understanding the typical challenges at each stage helps you anticipate and prepare:
| Stage | Team Size | Key Challenge | Primary Focus |
|---|---|---|---|
| Startup | 5-10 | Generalists stretched thin | Hiring first specialists |
| Early Growth | 10-20 | Communication overhead | First team splits, process basics |
| Growth | 20-35 | Coordination breakdown | Formal teams, first EM, platform |
| Scale | 35-50 | Alignment at distance | Tribes, guilds, architecture |
| Enterprise | 50+ | Organizational complexity | Multiple tribes, staff+ roles |
Each stage builds on the previous. The processes you establish at 10 engineers become the foundation for what works at 50. The culture you build when everyone knows each other becomes the default culture when most people are strangers. Invest early in practices that scale.
Common Scaling Pitfalls to Avoid
Even with the best intentions, engineering leaders make predictable mistakes when scaling. Here are the most common pitfalls and how to avoid them:
Hiring for speed over quality. When backlogs grow and pressure mounts, it is tempting to lower hiring standards to fill seats faster. This creates long-term problems that are harder to fix than the original capacity shortage. A bad hire at 50 engineers does more damage than at 5 because they affect more people and systems. Maintain high standards even when it slows hiring.
Clinging to the “old way” of working. Founders and early engineers often resist process changes that feel like bureaucracy. But what feels like unnecessary overhead at 10 people becomes essential coordination at 50. Recognize that different scales require different approaches. The practices that made you successful at 5 may prevent success at 50.
Underestimating communication overhead. Many scaling plans assume engineers will be as productive at 50 as they were at 5. They will not — at least not initially. Communication overhead, coordination costs, and onboarding burden reduce per-person output. Plan for this. Expect velocity to dip during transitions, then recover as new structures take hold.
Neglecting culture. Culture does not maintain itself. The behaviors you model, the stories you tell, and the values you reinforce become the culture — intentionally or not. At 50 engineers, you cannot personally influence everyone, so you need systems that scale culture: clear values, consistent hiring, and visible consequences for violations.
Over-engineering processes. The opposite of neglecting process is creating too much process too soon. Heavy processes designed for 100-person teams will crush a 20-person team. Add process incrementally, when the pain of not having it exceeds the overhead of having it. Start simple and evolve.
Building a Sustainable Engineering Culture at Scale
Beyond the specific strategies outlined above, successful scaling requires attention to the intangible factors that make engineering teams effective: psychological safety, intellectual honesty, and a growth mindset. These cultural elements are easy to maintain at small scale and easy to lose during rapid growth.
Psychological safety — the belief that one will not be punished for making mistakes — is essential for innovation. At 5 engineers, trust is built through daily collaboration. At 50, you need explicit practices: blameless postmortems, safe-to-fail experiments, and leaders who model vulnerability by admitting their own mistakes.
Intellectual honesty means evaluating ideas based on merit, not seniority or tenure. At small scale, the best idea usually wins because everyone is in the same room. At scale, you need mechanisms to surface ideas from junior engineers and remote team members: structured RFC processes, anonymous feedback channels, and leaders who actively solicit dissenting opinions.
A growth mindset — the belief that abilities can be developed through effort — becomes harder to maintain as teams specialize. Senior engineers may resist learning new technologies. Teams may become defensive about their code. Combat this by celebrating learning, rotating engineers across teams, and maintaining a culture where asking questions is valued more than appearing to know all the answers.
The Role of Leadership in Scaling
Engineering leaders set the tone for how scaling happens. Their behavior — what they prioritize, what they tolerate, what they celebrate — shapes the culture more than any written values statement.
Effective scaling leaders: Communicate context, not just instructions. Engineers need to understand why changes are happening to adapt their work accordingly. Protect the team from distractions. As the organization grows, demands on engineering time multiply. Leaders must shield the team from low-value meetings and initiatives. Make decisions with incomplete information. Scaling involves constant trade-offs. Leaders who wait for perfect information delay progress; those who decide too quickly create chaos. The skill is knowing which decisions are reversible and which require more deliberation. Invest in their own development. The skills that made someone a great 5-person team lead are different from those needed to lead 50. Leaders must grow alongside their teams.
The transition from individual contributor to manager to leader of managers is one of the hardest in tech. Many fail because they cling to what made them successful at the previous level. Successful scaling requires leaders who can let go of direct control and instead create systems that produce good outcomes.
Remote and Distributed Scaling Considerations
Since 2020, most engineering teams have become at least partially distributed. Scaling a distributed engineering team introduces additional challenges that co-located teams do not face: timezone coordination, asynchronous communication, and the difficulty of building relationships without in-person interaction.
Timezone overlap is the most significant constraint. Teams spread across more than 8 hours of timezone difference struggle to find synchronous collaboration time. When scaling distributed teams, consider timezone clustering — organizing teams so that most members have at least 4 hours of overlap. This enables real-time collaboration for urgent issues while preserving deep work time.
Asynchronous communication becomes essential. Document decisions in writing rather than relying on verbal communication. Record important meetings for those who cannot attend live. Establish clear response time expectations — not everything needs an immediate reply, but blocking issues should not wait 24 hours.
Relationship building requires intentional effort when distributed. Schedule informal video calls with no agenda. Create virtual spaces for non-work conversation. Bring teams together in person periodically — quarterly or bi-annually — to build the trust that makes remote collaboration effective.
Poland has emerged as a particularly attractive location for distributed engineering teams serving Western European and US East Coast markets. With strong English proficiency, cultural alignment with Western business practices, and timezone overlap with both regions, Polish engineers integrate well into distributed teams. The 520,000+ IT professionals in Poland provide a deep talent pool for companies looking to scale their engineering capacity.
Key Takeaways
- Hire managers early. The 1:5 manager-to-engineer ratio is optimal. Waiting until you are in crisis costs you your best engineers.
- Organize around missions. Structure teams around outcomes, not functions. Use the Spotify model principles, adapted to your context.
- Invest in onboarding. Structured 90-day onboarding reduces time-to-productivity from 6 months to 30-60 days.
- Enforce small PRs. Keep pull requests under 400 lines. Larger PRs have 40% more defects and take exponentially longer to review.
- Build platform teams. Dedicate a team to developer experience when you hit 25-30 engineers. Measure their impact through DORA metrics.
- Document decisions. Use Architecture Decision Records to capture context. Start at 10 engineers; by 50, they are essential.
- Standardize tools, customize processes. Reduce cognitive load with shared tools, but let teams adapt processes to their context.
- Measure outcomes, not activities. Focus on deployment frequency, lead time, stability, and developer satisfaction. Avoid gaming metrics.
- Create dual career ladders. Make the IC track equivalent to management. Not everyone should be forced into management to advance.
- Manage debt strategically. Allocate 20% capacity to debt reduction. Classify debt by impact and fix blocking debt first.
Frequently Asked Questions
When should I hire my first engineering manager?
Hire your first engineering manager when you hit 8-10 engineers. At this size, the founding technical lead is likely spending 30-50% of their time on management activities — interviews, 1:1s, code reviews, planning. A dedicated manager frees them to focus on technical leadership while providing the management attention your growing team needs.
How do I structure teams at 20 engineers?
At 20 engineers, you typically have 3-4 teams of 5-7 people each. Organize around business domains or user journeys rather than technical layers. Each team should have the skills needed to deliver end-to-end value — backend, frontend, and ideally some product/design input. Keep teams stable for 6-12 months to allow relationships and processes to gel.
What is the optimal manager-to-engineer ratio?
Research from Jellyfish across 445 companies shows the average working ratio is 1:5. Ratios above 1:8 correlate with higher turnover — 64% of departing engineers had managers with above-average ratios. Google, Microsoft, and Amazon maintain ratios around 1:6-9, while Netflix operates at 1:5-6. The right ratio depends on your context, but 1:5-6 is a safe target.
When do I need a platform team?
You need a platform team when infrastructure and tooling work exceeds what product teams can handle alongside feature work. This typically happens at 25-30 engineers. Signs you need a platform team: deployment pipelines breaking frequently; teams duplicating infrastructure work; developers spending more than 20% of time on tooling rather than features.
How do I maintain culture while scaling?
Culture does not maintain itself — it must be actively cultivated. Document your values and the behaviors that exemplify them. Use them in hiring decisions, performance reviews, and promotion criteria. Create rituals that reinforce culture: all-hands meetings, demo days, hackathons. Most importantly, ensure leadership models the culture consistently. Culture is what you do, not what you say.
How much should I invest in technical debt reduction?
Allocate 15-25% of engineering capacity to debt reduction, with 20% being a common target. This is enough to make meaningful progress without starving feature development. The key is being strategic — fix blocking debt first, schedule high-impact debt for upcoming quarters, and document acceptable trade-offs. Treat debt as a normal part of engineering work, not a crisis to be solved in all-nighters.
What if my team is resistant to process changes?
Resistance to process changes is natural, especially from early team members who remember when things were simpler. Address this by: explaining why the change is necessary (connect to business outcomes); involving the team in designing the new process; starting with a pilot on one team; measuring and sharing results; and being willing to iterate. Some early employees may decide the new stage is not for them — that is okay.
How do I know if we are scaling too fast?
Signs you are scaling too fast include: new hires are not reaching productivity within 90 days; code quality metrics are declining; key engineers are leaving; communication breakdowns are frequent; and technical debt is accumulating faster than it is being addressed. If you see multiple of these signs, pause hiring and focus on stabilizing your current team before adding more people.
Sources
- Fullscale.io — Engineering Team Scaling Strategies: From 5 to 50 Without Losing Code Quality (2025)
- Jellyfish — The Silent Drain: How Unbalanced Manager to Engineer Ratios Hurt Developer Retention (April 2025)
- SI Labs — Spotify Model: Squads, Tribes, Chapters, and Guilds (2025)
- PropelCode — The Impact of PR Size on Code Review Quality: What Data Tells Us (2025)
- Daily.dev — Developer Onboarding: The First 90 Days Playbook (2025)
- Fullscale.io — The 90-Day Developer Onboarding Best Practices That Actually Works (2025)
- InformationWeek — Building High-Performance Tech Teams in 2025: A Practical Scaling Guide (2025)
- Engineering Manager Tools — Pull Request Size: The Metric That Improves All Others (2025)




