
For enterprise data leaders and CTOs planning a modern data platform, the pressure to deliver ROI on analytics and AI initiatives is immense. In the race to become data-driven, many organizations make a critical hiring mistake: they hire data scientists before establishing a solid data foundation. Understanding the distinction between data engineer vs data scientist roles is essential to avoid wasting budget and slowing down your AI roadmap. This article explores why hiring the wrong data role slows analytics and AI initiatives, and why building a data engineering team should be your first priority.
The Cost of Hiring the Wrong Data Role
When enterprise innovation units in FinTech, Software, and Media sectors set out to build AI capabilities, the instinct is often to hire data scientists immediately. However, data scientists require clean, accessible, and well-structured data to build models and generate insights [1]. Without a robust data infrastructure, highly paid data scientists end up spending up to 80% of their time performing janitorial data work—cleaning and organizing raw data—rather than developing predictive models [2].
This misallocation of resources is a primary reason why many enterprise AI initiatives fail. According to industry research, a significant percentage of AI projects stall or fail to deliver expected ROI due to poor data quality and lack of AI-ready infrastructure [3]. When you hire a data scientist to “deploy AI” without providing product engineering support, you create a slow-motion failure where months pass with only promising notebooks and frustrated stakeholders to show for the investment [4].
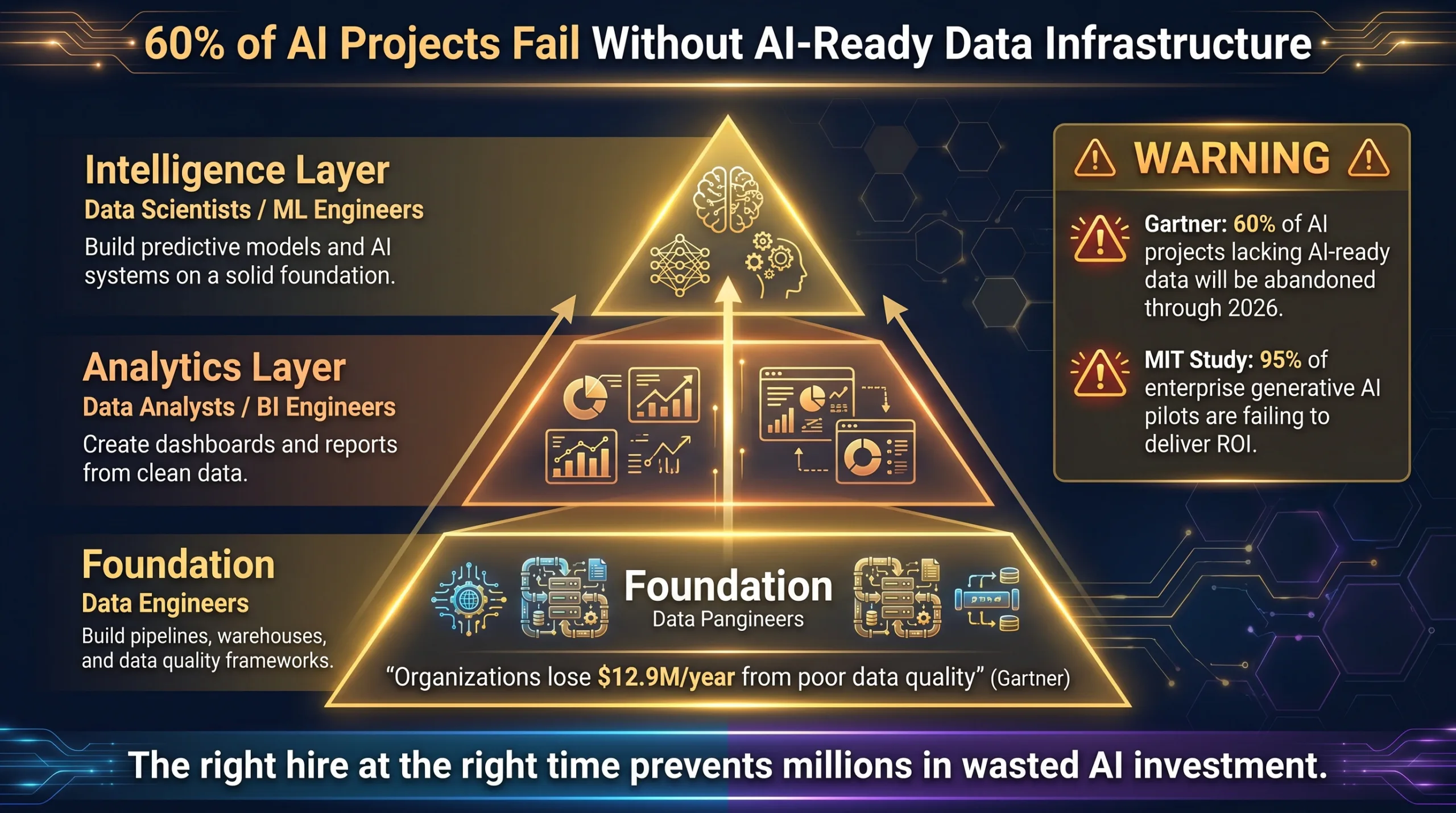
Distinguishing Data Roles: Data Science vs Engineering
To build a successful data analytics team, it is crucial to understand the distinct responsibilities and skill sets of data engineers and data scientists.
What is a Data Engineer?
A data engineer is the architect and builder of your data infrastructure. They design, construct, and maintain scalable data pipelines that extract, transform, and load (ETL) data from various sources into centralized repositories like data warehouses or data lakes [5]. Their primary goal is to ensure that data is accurate, reliable, and accessible for analysis.
Key responsibilities of a data engineer include:
- Building and maintaining data pipelines and architectures.
- Ensuring data quality and implementing validation frameworks.
- Optimizing database performance and scalability.
- Managing cloud infrastructure (e.g., AWS / Azure / GCP engineers team).
What is a Data Scientist?
A data scientist is the analytical engine of your team. They leverage statistical methods, machine learning algorithms, and domain expertise to extract actionable insights from data [5]. Data scientists use the clean data provided by data engineers to build predictive models, test hypotheses, and solve complex business problems.
Key responsibilities of a data scientist include:
- Developing machine learning models and predictive algorithms.
- Conducting exploratory data analysis to identify trends and patterns.
- Designing experiments and A/B tests.
- Communicating data-driven insights to stakeholders through data visualization.

Data Team Roles Comparison
| Feature | Data Engineer | Data Scientist |
|---|---|---|
| Primary Focus | Infrastructure, pipelines, and data quality | Analytics, modeling, and insights |
| Key Output | Clean, accessible data repositories | Predictive models and actionable insights |
| Core Skills | SQL, Python, Java, ETL tools, Cloud platforms | Python, R, Statistics, Machine Learning |
| Business Value | Enables scalable analytics and prevents data chaos | Drives strategic decisions and innovation |
Why You Should Hire Data Engineers First
For Fortune 5000 companies and large tech enterprises, the foundation of any successful data strategy is a robust infrastructure. Here is why your first hire should be a data engineer:
1. Establishing a Single Source of Truth
Data engineers integrate disparate data sources, resolving inconsistencies and deduplicating records. This ensures that when your business leaders look at a dashboard, they are making decisions based on accurate and reliable information [2].
2. Enabling Scalability
Ad-hoc data solutions might work for a small startup, but they quickly collapse under the weight of enterprise data volumes. A cloud engineering team can design a modern data architecture that scales seamlessly, decoupling compute from storage to handle petabytes of data [2].
3. Maximizing the ROI of Data Scientists
By hiring data engineers first, you automate the ETL processes and deliver clean, modeled tables to your analysts. This allows your data scientists to focus entirely on high-value tasks like finding patterns and predicting churn, rather than wrangling messy data [2].

Building Your Data Team with Correct Context
Building an in-house data team from scratch can be time-consuming and expensive, especially in highly competitive markets like the East Coast US, UK, DACH, and Nordics. For enterprises looking to scale engineering teams efficiently, partnering with an employer of record Europe or a specialized nearshoring partner offers a strategic advantage.
At Correct Context, we specialize in helping enterprises hire developers Poland and build an extended engineering team in Central and Eastern Europe (CEE). Whether you need a dedicated development team, an offshore development team, or a specialized big data development team, we provide comprehensive solutions including recruitment, payroll, HR, and office management. This allows you to hire in Europe without company entity setup, ensuring full employment compliance.
Our expertise spans across AI development team building, machine learning engineers team scaling, and establishing a robust platform engineering team. By leveraging our services, you can access affordable senior developers and build a tech hub in Poland, accelerating your AI and data initiatives without the overhead of local infrastructure.
Conclusion
When planning your data platform, the choice between hiring data engineers and data scientists is clear: infrastructure must precede analytics. By prioritizing data engineers, you build a scalable foundation that ensures data quality, prevents analytics failures, and empowers your future data scientists to deliver true business value. For enterprises looking to accelerate this process, leveraging a nearshore development team in Europe offers a cost-effective and scalable solution to build your core IT teams.
References
[1] Data Engineer vs. Data Scientist: What’s the Difference?, Coursera, Nov 26, 2025.
[2] Hire Data Engineers First: The Strategic Foundation for Scalable Analytics, Dataforest, Dec 11, 2025.
[3] Why 95% of AI Projects Fail and How Data Fixes It, SR Analytics, Feb 26, 2026.
[4] Data Scientist or AI Engineer? The Hiring Mistake That Slows AI Teams, ODSC, Feb 13, 2026.
[5] Data Science vs Data Engineering, Dataquest, Feb 2, 2026.




